Resources (AI, Engg)
karpathy intro to llms: https://youtu.be/zjkBMFhNj_g
- tree of thought: system 2
- self-improvement beyond imitating humans
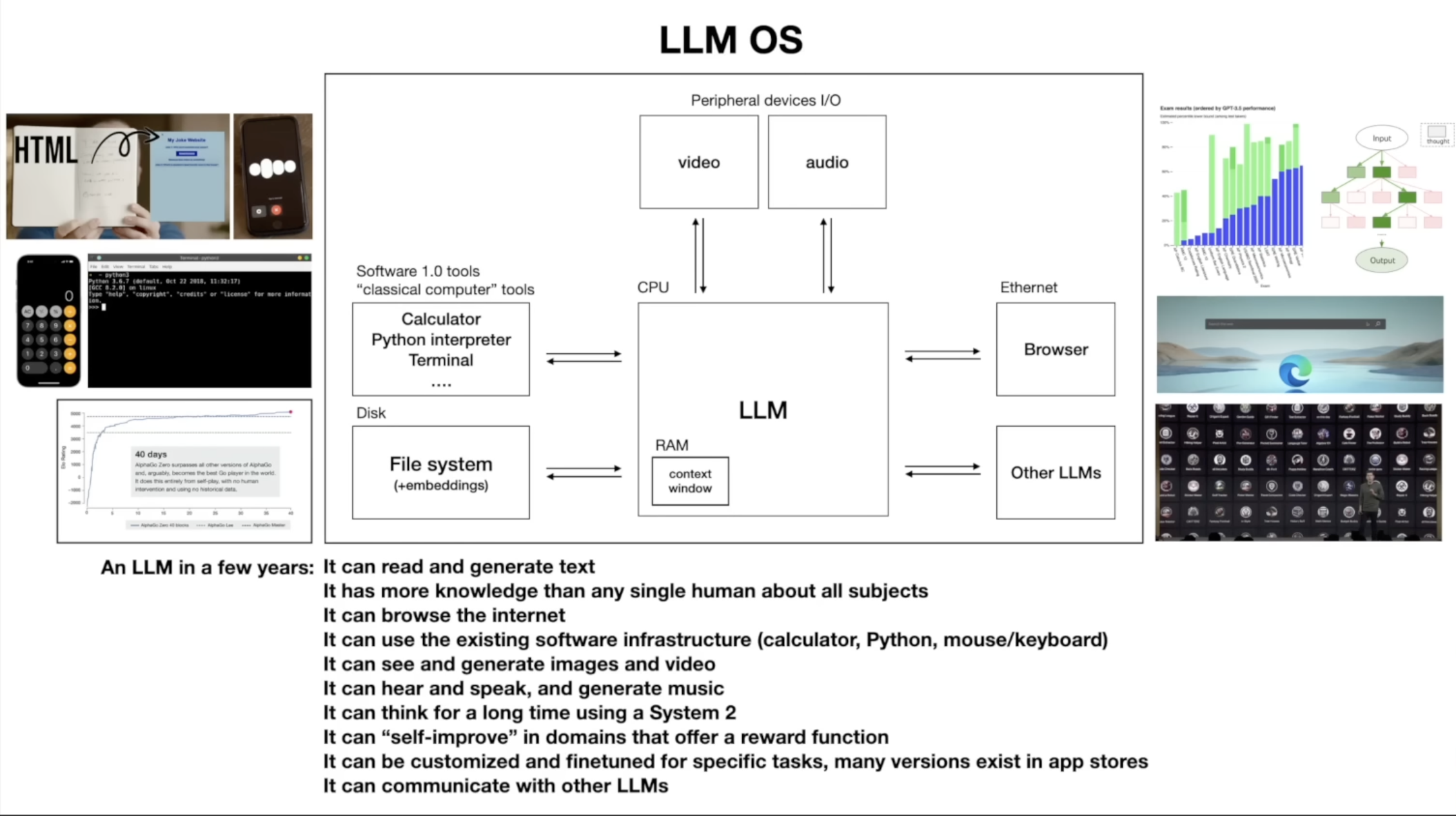
AI engineer AI Engineering 201 https://youtu.be/N7lJY5IKVLE (part I and II)
https://www.anyscale.com/blog/a-comprehensive-guide-for-building-rag-based-llm-applications-part-1#evaluation
- chunking: Smaller chunks (but not too small!) are able to encapsulate atomic concepts which yields more precise retrieval. While larger chunks are more susceptible to noise. Popular strategies include using small chunks but retrieving a bit of the surrounding chunks around it (since it may have relevant info) or store multiple embeddings per document (ex. summary embedding per document).
- chunking: More chunks will allow us to add more context but too many could potentially introduce a lot of noise.
- we will not be be exploring fine-tuning our LLM in this section because our previous experiments (LoRa vs. full parameter) have shown that fine-tuning has helped tremendously with form not facts, which in our case won’t help too much (compared to for ex. SQL generation). However, your use cases might benefit from fine-tuning
- embedding fine-tuning: full embedding model or just the token embedding layer of the embedding model
- we have empirically found that improving the quality of our retrieval system and the data flywheel (where we fix our documentation itself) has had a much larger impact on the overall quality of our system.
- We’re going to now supplement our vector embedding based search with traditional lexical search, which searches for exact token matches between our query and document chunks. Our intuition here is that lexical search can help identify chunks with exact keyword matches where semantic representation may fail to capture. Especially for tokens that are out-of-vocabulary (and so represented via subtokens) with our embedding model. But our embeddings based approach is still very advantageous for capturing implicit meaning, and so we’re going to combine several retrieval chunks from both vector embeddings based search and lexical search.
- The number of chunks (k) has been a small number because we found that adding too many chunks did not help and our LLMs have restricted context lengths. However, this was all under the assumption that the top k retrieved chunks were truly the most relevant chunks and that their order was correct as well. What if increasing the number of chunks didn’t help because some relevant chunks were much lower in the ordered list. And, semantic representations, while very rich, were not trained for this specific task. In this section, we implement reranking so that we can use our semantic and lexical search methods to cast a much wider net over our dataset (retrieve many chunks) and then rerank the order based on the user’s query.
- Note: we didn’t omnisciently know to create these unique preprocessing functions! This is all a result of methodical iteration. We train a model → view incorrect data points → view how the data was represented (ex. subtokenization) → update preprocessing → iterate ↺
- However, we want to be able to serve the most performant and cost-effective solution. We can close this gap in performance between open source and proprietary models by routing queries to the right LLM according to the complexity or topic of the query. For example, in our application, open source models perform really well on simple queries where the answer can be easily inferred from the retrieved context. However, the OSS models fall short for queries that involve reasoning, numbers or code examples. To identify the appropriate LLM to use, we can train a classifier that takes the query and routes it to the best LLM.
- In order to implement this, we hand-annotated a dataset of 1.8k queries according to which model (gpt-4 (label=0) or codellama-34b (label=1)) would be appropriate – by default we route to codellama-34b and only if the query needs more advanced capabilities do we send the query to gpt-4. We then evaluate the performance of the model on a test dataset that has been scored with an evaluator.
- Note: For our dataset, a small logistic regression model is good enough to perform the routing. But if your use case is more complex, consider training a more complex model, like a BERT-based classifier to perform the classification. These models are still small enough that wouldn’t introduce too much latency. Be sure to check out this guide if you want to learn how to train and deploy supervised deep learning models.
-
data flywheel: Creating an application like this is not a one-time task. It’s extremely important that we continue to iterate and keep our application up to date. This includes continually reindexing our data so that our application is working with the most up-to-date information. As well as rerunning our experiments to see if any of the decisions need to be altered. This process of continuous iteration can be achieved by mapping our workflows to CI/CD pipelines. A key part of iteration that goes beyond automated reindexing, evaluation, etc. involves fixing our data itself. In fact, we found that this is the most impactful lever (way beyond our retrieval and generation optimizations above) we could control Users use the RAG application to ask questions about the product.
Use feedback (👍/👎, visited source pages, top-k cosine scores, etc.) to identify underperforming queries.
Inspect the retrieved resources, tokenization, etc. to decide if it’s a shortcoming of retrieval, generation or the underlying data source.
If something in the data can be improved, separated into sections/pages, etc. → fix it!
Evaluate (and add to test suite) on previously underperforming queries.
Reindex and deploy a new, potentially further optimized, version of the application.
12 Lessons, Get Started Building with Generative AI 🔗 https://microsoft.github.io/generative-ai-for-beginners/
Principles for Prompt Engineering: https://www.youtube.com/watch?v=6d60zVdcCV4
- Claude loves XML tags, many people miss that when using Claude models
- Apart from CoT, can give criteria and instead of outputting CoT explanation, can ask to print critique and then, give a final answer
- Use a scoring mechanism in the case of a recommendation task instead of binary yes/no recommendation
- Decomposition based prompting: ask the model to decompose the model into multiple sub-questions that can be answered independently and use the results of this decomposition to finally give the answer as opposed to raw CoT where each step influences the subsequent step, reduces the bias.
Pydantic is all you need: https://youtu.be/yj-wSRJwrrc
Step-back prompting: https://cobusgreyling.medium.com/a-new-prompt-engineering-technique-has-been-introduced-called-step-back-prompting-b00e8954cacb
- given a question that requires complex reasoning, ask the model to first generate a step-back question that targets the underlying principles behind the original question
- generate the answer to the stepback question
- feed the original question, step back question, step back question’s answer to generate the final answer.
langchain example: https://github.com/langchain-ai/langchainjs/blob/main/cookbook/step_back.ipynb?utm_source=www.superpowerdaily.com&utm_medium=newsletter&utm_campaign=openai-dev-day-is-here
New prompt engineering trick: Telling GPT-4 you’re scared or under pressure improves performance
In a recent paper, researchers have discovered that LLMs show enhanced performance when provided with prompts infused with emotional context, which they call “EmotionPrompts”. These prompts incorporate sentiments of urgency or importance, such as “It’s crucial that I get this right for my thesis defense,” as opposed to neutral prompts like “Please provide feedback.”
“We design 11 sentences as emotional stimuli for LLMs, which are psychological phrases that come after the original prompts.” “Finally, we analyze the performance of the combination of various emotional prompts and find that they can further boost the results”
summary post: https://www.reddit.com/r/ChatGPTPro/comments/17mkf5s/telling_gpt4_youre_scared_or_un[…]com&utm_medium=newsletter&utm_campaign=openai-dev-day-is-here paper: https://arxiv.org/pdf/2307.11760.pdf

course: https://www.youtube.com/playlist?list=PLrw6a1wE39_tb2fErI4-WkMbsvGQk9_UB
read instruct gpt: https://arxiv.org/pdf/2203.02155.pdf reading Flamingo: a Visual Language Model for Few-Shot Learning (GPT3 moment for multimodal models): https://arxiv.org/pdf/2204.14198.pdf We propose key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities. For tasks lying anywhere on this spectrum, a single Flamingo model can achieve a new state of the art with few-shot learning, simply by prompting the model with task-specific examples. On numerous benchmarks, Flamingo outperforms models fine-tuned on thousands of times more task-specific data.
- multimodal blog post by chip: https://huyenchip.com/2023/10/10/multimodal.html#part_1_understanding_multimodal
- read state of ai report: https://docs.google.com/presentation/d/156WpBF_rGvf4Ecg19oM1fyR51g4FAmHV3Zs0WLukrLQ/edit#slide=id.g24daeb7f4f0_0_5709
-
Let’s verify step by step: https://docs.google.com/presentation/d/156WpBF_rGvf4Ecg19oM1fyR51g4FAmHV3Zs0WLukrLQ/edit#slide=id.g24daeb7f4f0_0_5709
-
read Dawn of LLMs
- newsletters: latent space, sebastian raschka, chip huyen
- hackers guide to building LLMs, state of gpt, building gpt from scratch
- illustrated guides from jay alammmar
- deeplearning.ai short courses
- cs 224n, stanford cs NLU course, stanford computer basics course, stanford probability course
- generative AI with llms coursera course
- communities: generative AI, maxpool
AI
Foundations
MLOps
- [course] Deep Learning course by FSDL
- [post] MLOps Guide by Chip Huyen
- [course] [pending] MLOps Specialisation by Deeplearning.ai
- [course] [pending] ML for Developers by MadeWithML
LLMs
- [course] [new content] CS224N: Natural Language Processing with Deep Learning by Stanford
- [course] [in progress] XCS224U: NLU by Stanford
- [course] [pending] CS324 - Large Language Models by Stanford
- [course] [pending] Understanding Large Language Models by Princeton
- [course] LLM bootcamp by FSDL
- [post] Building LLM applications for production by Chip Huyen
- [post] RLHF: Reinforcement Learning from Human Feedback by Chip Huyen
- [repo] An open collection of methodologies to help with successful training of large language models and multi-modal models
Libraries
Prompt Engineering
- [website] Prompting Guide
- [website] Learn Prompting
- [post] [pending] Prompt Engineering by Lilian Weng
- [repo] [pending] Brex's Prompt Engineering Guide